
Data Access Still Matters
This blog post was inspired by Bill Karwin’s book SQL Antipatterns:Avoiding the Pitfalls of Database Programming. I read this over Thanksgiving weekend. If you are a developer, and you do database work, this is on the must-read list.
I agreed with just about everything in his book except a few little details. In Chapter 4, “ID Required,” Mr. Karwin lays out two antipatterns.
- The primary key is always an autoincrementing column named
id. - The primary key is not necessary when there is another unique restriction present naturally in the data.
Regarding the First
The first condition is something like this.
CREATE TABLE employees (
id INT NOT NULL IDENTITY(1, 1),
last_name VARCHAR(64) NOT NULL,
first_name VARCHAR(64) NOT NULL,
department_id INT NOT NULL,
-- ...
CONSTRAINT [pk_employees] PRIMARY KEY CLUSTERED ([id] ASC)
);
I agree that not every table requires a primary key named id. There are lots of situations where not using id or not having autoincrementing values is helpful. However, understand that with technologies like NHibernate with fluent mapping or Rails’ ActiveRecord, it is terribly damn convenient for the developer.
NHibernate with explicit mapping won’t much matter, since you must define the exact purpose of each and every column. It’s only when you’re using some of the implicit mapping magic that this comes into play.
Also, if you’re using PostgreSQL, there is some syntactic sugar you can use when joining tables.
-- Using id
SELECT e.id AS employee_id, e.first_name, e.last_name, SUM(te.total_hours) AS sum_total_hours
FROM employees e
INNER JOIN time_entries te ON e.id = te.employee_id
WHERE te.entry_date = N'2013-06-16'
GROUP BY e.id, e.first_name, e.last_name
-- Using table-specific columns
SELECT e.employee_id
SELECT e.id AS employee_id, e.first_name, e.last_name, SUM(te.total_hours) AS sum_total_hours
FROM employees e
INNER JOIN time_entries te USING (employee_id)
WHERE te.entry_date = N'2013-06-16'
GROUP BY e.id, e.first_name, e.last_name
In the above example, you can use the USING keyword to join two tables on columns when the names match. If you’re explicit about calling the Employee ID employee_id instead of id, you can take advantage of syntax.
Consider your data access. If you think you’ll be handcrafting a lot of SQL, then maybe this syntactic sugar is worth it. Are you using a database where this even matters? Are you using a data access tool (NHibernate with fluent mapping, ActiveRecord) that takes advantages of the primary key being called id? There’s a lot to consider here beyond, “Don’t do it.”
Regarding the Second
Mr. Karwin also describes the following as an antipattern.
CREATE TABLE users (
user_id INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
username VARCHAR(64),
-- ...
);
CREATE UNIQUE INDEX [unique_username] ON [users] ([username]);
He says that this table has two unique identifiers, since both user_id and username unique identify a row. So I tried this in my Portfolio project. I have the ability to create tags and apply these tags to events. The slug for these tags are each unique. So I tried dropping the id column in favor of just using the slug column as the primary key. I made sure to turn on cascading updates every place a tag was referenced. Imagine my surprise when I saw this error message when I tried to edit a tag.
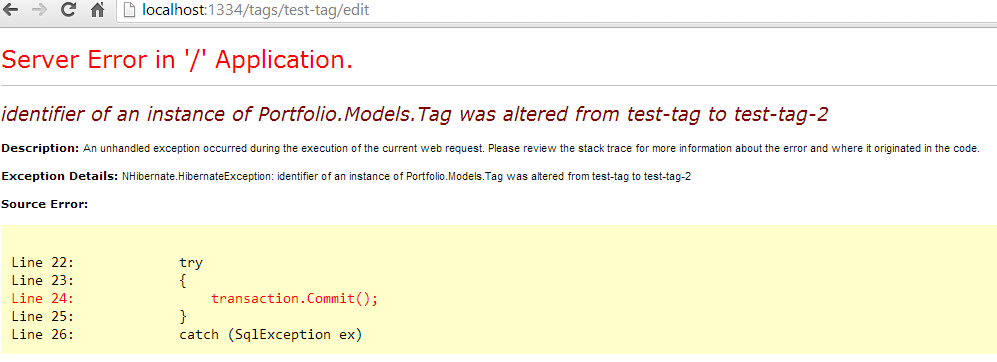
OK, I wasn’t surprised. I knew this would happen. But only because I’ve been burned by it before.
NHibernate won’t let you change the primary key of a loaded record. As it turns out, neither will Entity Framework or ActiveRecord. So I would offer up just one little addendum to the second snafu. It is fine to use a real-valued column if that value isn’t going to change, depending on what kind of data access technology you are using in your application. Are usernames allowed to change? Are tag slugs going to be modified? Are you sure employees never get the social security numbers wrong? If so, I wouldn’t recommend using those as primary keys — with or without cascading.