
Prepping and Inspecting SQL Server
![]()
Imagine you are a consultant, and you want to come in and inspect a SQL server architecture. How would you do it? What would you look for? What questions would you ask? Here’s a checklist of ideas.
This is a “living document” for prepping an instance of SQL Server. If you have suggestions, please send them to jarrettmeyer at gmail dot com.
Configuration
- Ensure that your databases are not on your C: drive. Databases can grow and take all of the space on C:. This is bad. This is especially true of TempDB.
- Ensure that your data folders and backup folder are one different drives. We often see scenarios were the data is stored in
S:\SQL Server\Dataand backups are stored onS:\SQL Server\Backups. This is not ideal. If you lose yourS:drive, you can lose both your data and your backups. Even in a RAID scenario, the RAID controller itself can fail, leading to inaccessible data. -
(SQL Server 2016) Ensure that the query store option is enabled on all databases. This allows SQL server to retain information about query plans and performance. This is done with the following command.
ALTER DATABASE <database> SET QUERY_STORE = ON; - Compare databases and system architecture between Production and non-production instances.
– Check the system hardware. To get good comparisons between a test/staging environment and a production environment, hardware should be identical. If it is not identical, then metrics collected in test/staging may not be reliable.
– Ensure that databases have similar amounts of data in Production and non-production environments. I have seen scenarios where Production data has millions or billions of rows, while a test environment only has a few thousand rows of data. Obviously, you cannot troubleshoot performance between the systems.
– Ensure that databases have the same recovery mode in Production and non-production environments. If a database hasFULL RECOVERYmode in production, butSIMPLE RECOVERYin test, you may find that test is faster than production.
– If you are using Developer Edition in test and Standard Edition in Production, you can run into threading and parallelism issues. Developer Edition has the same feature set as Enterprise Edition, so it will use every bit of compute and memory available. However, Standard Edition has caps on CPU, RAM, and degrees of parallelism! For example, the newCOLUMNSTORE INDEXis now available in all versions of SQL Server as of 2016 SP1. But, as usual, you get what you pay for. In Enterprise Edition, it will use every thread it can; Standard Edition will use up to 2 threads; Web & Express Editions will use just 1 thread. In a query execution plan, you can see the degrees of parallelism under “Properties”. -
Ensure that your databases are not owned by user accounts. By default, a database is owned by the user who created the account. Databases should be owned by a non-user account. Either a single domain account should own all databases, or SA should own all databases.
ALTER AUTHORIZATION ON DATABASE::<your database name> TO sa; - Are there databases that are not using the latest compatibility mode for the installed version of SQL server? If so, are these reasons documented in a shared location so that all future programmers, DBAs (consultants, etc.) will know why these databases should not be upgraded to a later compatibility mode?
Installing Useful Procedures
- Install Adam Machanic’s
sp_WhoIsActive. This is a super handy script that tells you who is connected to your server and what is running. It can be downloaded from whoisactive.com/downloads. - Install Ola Hallengren’s maintenance scripts. They can be downloaded from ola.hallengren.com/downloads.html.
- Install Brent Ozar’s SQL Server First Responder Kit. This includes
sp_Blitzand several other very useful procedures. These scripts can be downloaded from github.com.
Setting Alerts
-
Add an alert for TempDB Growing. This should be set to an appropriate value relative to the disk holding TempDB.
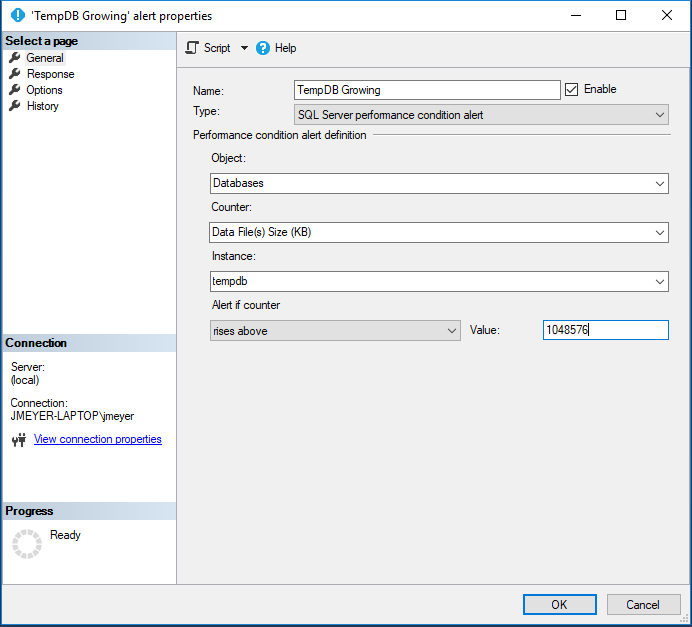
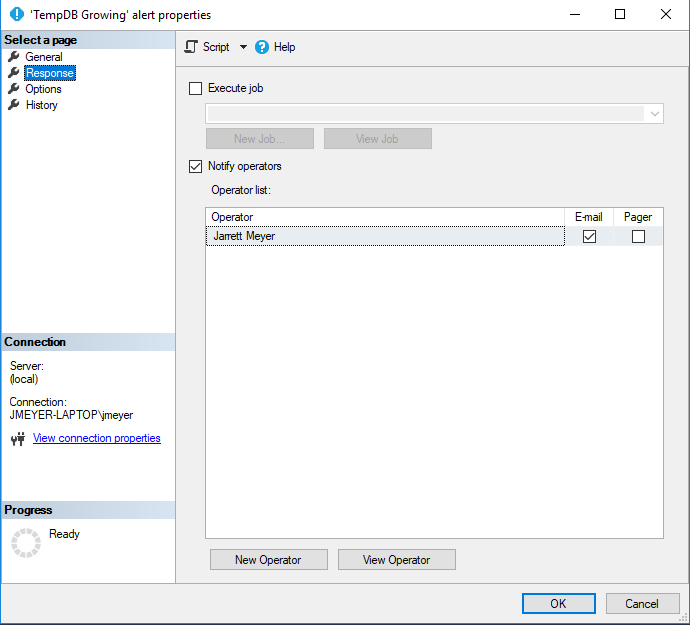
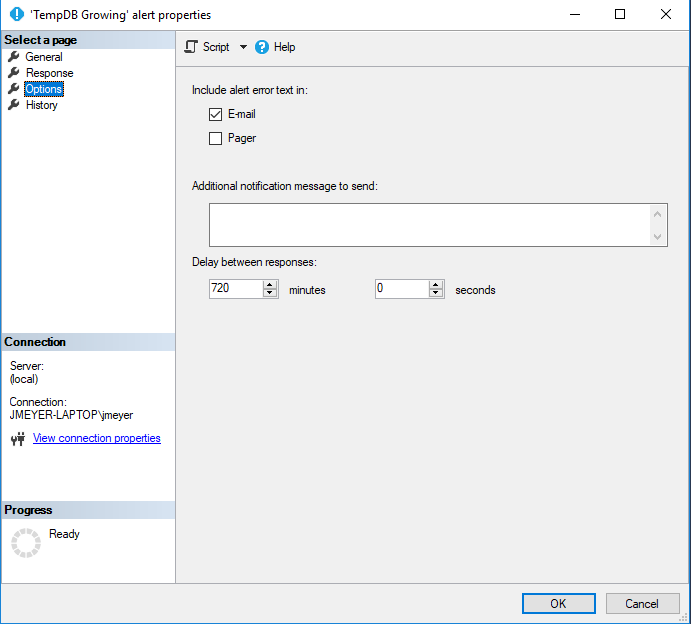
- For any sufficiently large databases, set a disk size alert. This is done similarly to setting a disk size alert for TempDB, shown above.
- Ensure that all SQL Agent Jobs have notifications enabled for failure conditions. Ideally, all agent jobs will send a failure notification email to a shared proxy account (e.g. dba@mycompany.com). Agent jobs should never fail silently.
Maintenance Plans
- Ensure that you have a maintenance plan to run
CHECKDBon all databases.CHECKDBperforms several functions in your database. - Ensure that you have a maintenance plan to backup all databases.
- Ensure that you have a maintenance plan to backup all transaction logs.
- Create a maintenance plan to clean up MSDB history.
- Create a maintenance plan to delete old backup files. All of those backups can start chewing up a lot of disk. This can either be part of the maintenance plan to clean up MSDB history (above), or it can be its own maintenance plan. Either way, you will want to keep the age of backups the same (e.g. 2 weeks).
- Provided you have a dedicated maintenance window or sufficiently small indexes, create a maintenance plan to clean up indexes. Indexes with > 30% fragmentation and over 1,000 pages should be rebuilt. Indexes with > 5% fragmentation and over 1,000 pages should be reorganized. (We don’t care about small indexes. Who cares if small indexes are fragmented?) This operation is a blocking operation. If you do not have a maintenance window, or if your database is large enough to make this an unacceptably slow process, this should not be a maintenance task.
Interview Questions
These questions will require you to talk to DBAs or system administrators.
- What is the policy for offsite backups?
- What is the business expectation for a system restore time window? These should be broadly defined (e.g. zero time, less than one minute, less than one hour, less than four hours, less than one day). Different expectations will have different costs. If your expectation is zero time and zero data loss, expect this to be the most expensive option, as there is nothing natively built into SQL Server to allow for zero downtime and zero data loss. If your expectation is under one minute, then SQL Server comes equipped with features such as failover clusters, replication, and Always On (2016 and newer). At under one hour, a human should be able to answer a pager and restore backups and transaction logs, provided all drive provisioning is online and accessible. At under four hours, drives can be repartitioned. At under one day, a server can be rebuilt, RAID controllers can be next-day-aired, offsite backups can be downloaded, and a database can be provisioned from scratch.
- What policies exist to warm up buffers and caches? When changes to tables or indexes are published, are there processes or procedures that will execute common queries, especially queries where having data readily available in cache makes a significant performance difference.
- Is reference data stored in its own schema (e.g.
[ref].*)? Because reference data (e.g. area codes, counties, countries, genders, U.S. states) should rarely change, policies for your reference schema can be different than your policies for other transactional data. Note: This question is important for applications with small maintenance windows. - Are service-level objectives (SLOs) well defined and documented? What are they? (See below for an example SLO table.)
- Where is the architectural inventory? This is a list of all machines (physical and virtual) and their primary roles. This should include databases, application servers, Active Directory servers, file servers, email servers, load balancers, etc. This inventory should include offsite/cloud infrastructure.
- How are bulk-process job logs stored, and how often are they reviewed?
Sample SLO table.
| Operation | Objective | Measure | Description |
|---|---|---|---|
| New customer signup | Availability | 99.9% | 99.9% of all requests are served. |
| Latency (total page load) | 0.10 - 1.00 s | All API requests are returned within 1s from a hardline machine. | |
| Allowed errors per day | 5 | Total number of server errors returned to all clients per day. | |
| Peak new customer signups per minute | 100 | What is the expected peak usage? How many assets and API requests must be fulfilled to meet this requirement? |
Public-Facing Applications
These will apply if you have public-facing applications.
- How are page metrics collected? How often are metrics reviewed? How often is each page requested? What is the load time for each page?
- How many database requests are required for each page or API request? How is this monitored?
Personal Notes
Just a few of my notes, and why we ask some of these questions.
- In my time working with applications, I have had RAID controllers fail twice. It doesn’t matter how reliable your RAID 10 disks are if the controller itself fails. For some companies, that may mean having replicated SANs.
- Despite it being key part of a quality design, I have never seen a SLO table like the one shown above. Most business analysts I work with are barely able to keep up with business process requirements, let alone come up with applicable performance measures.